Form a linked list
Contents
13.2. Form a linked list#
13.2.1. What is a node in the list?#
To form a linked list, we need to define the data type of the node, which is an element, in a linked list. Since each node in the linked list contains a value/data and a link to the next node, the node has to be a data structure that holds two different type members. To represent the value, we can use an int, and to represent the link, we can use a pointer to a node.
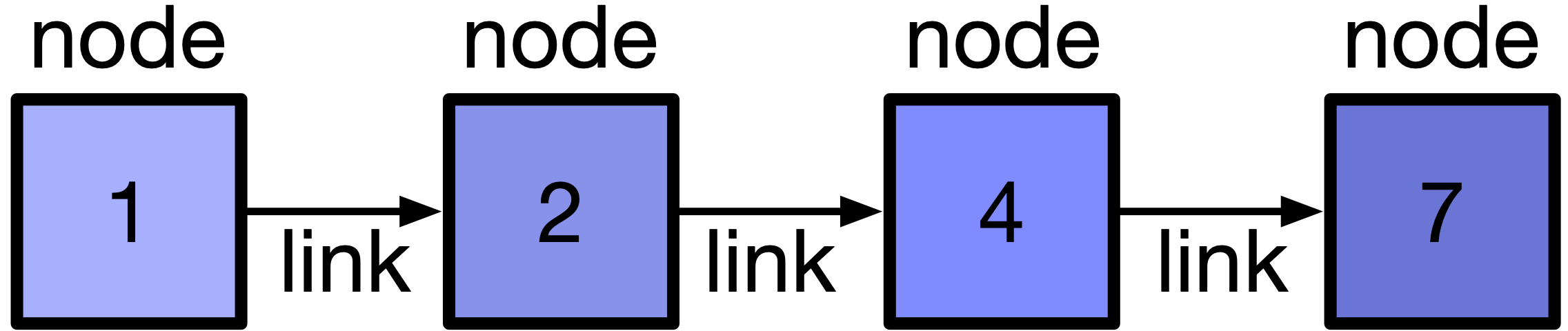
We can define the node as follows:
struct node {
int data;
struct node *next;
};
To make it easier, we will create an alias for struct node as Node. This way, we can use Node instead of struct node when we define a variable of type Node.
typedef struct node {
int data;
struct node *next;
} Node;
13.2.2. Create a node#
In the following code, we declare a node variable named nodeFirst and set it’s data to 1 and next to NULL. NULL is a special address value at address 0. It is used to indicate that there is no next node.
Then, to add another node in the list, we declare another node variable named nodeSecond and set it’s data to 2 and next to NULL.
We link the two nodes by getting the address of nodeSecond and assigning it to nodeFirst.next.
(*nodeFirst.next).data is the data stored in the node pointed to by nodeFirst.next, which is the data member in nodeSecond.
Code
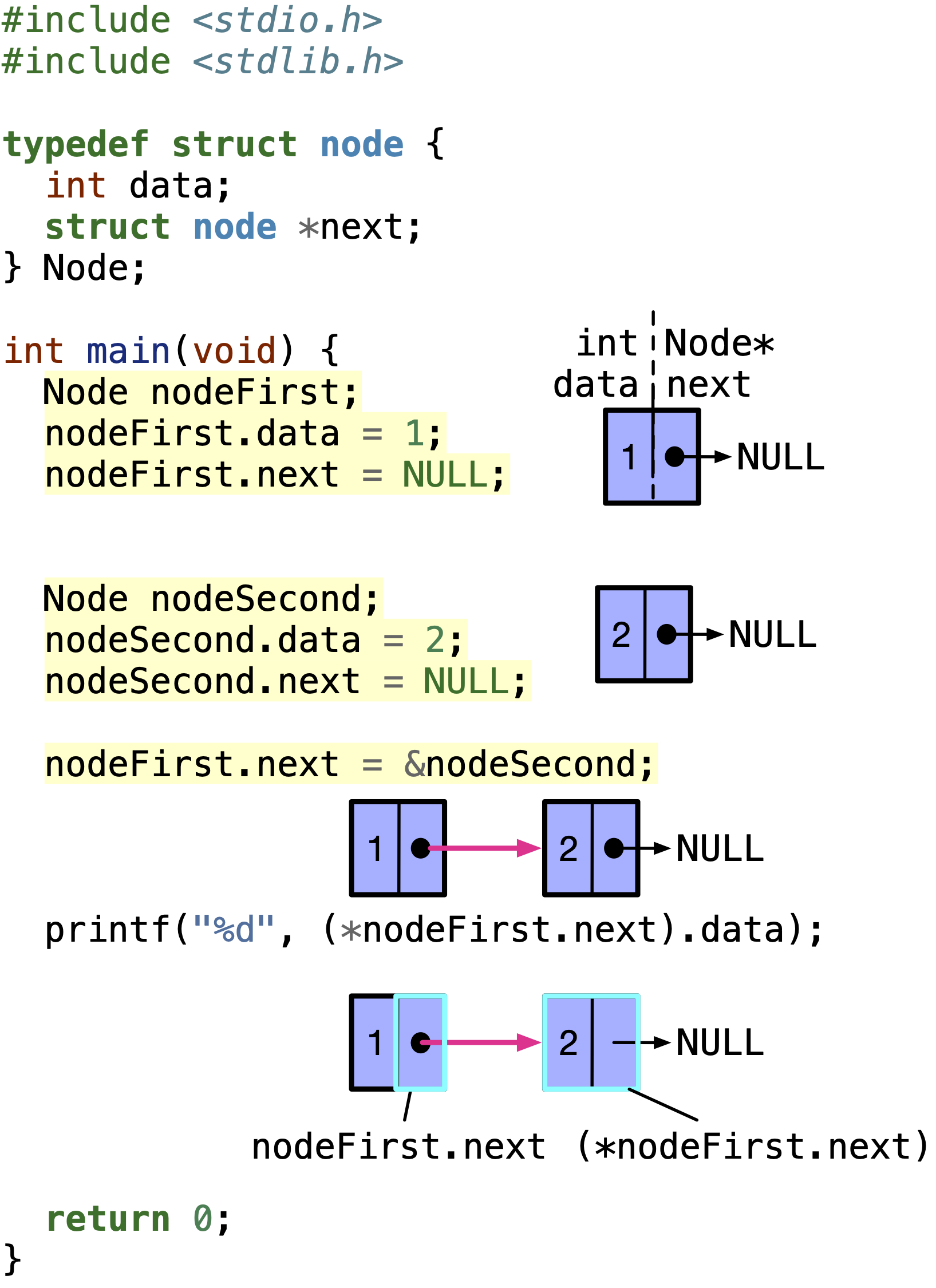
Output
2
As observed in the figure above, we had to declare a node with a new variable name for every node in the list. This is not very efficient for two main reasons:
For many
Nodevariables in the list, we need many variable names.If we were to declare a
Nodevariable in a function, then return from that function, Once a function returns, its memory space gets freed for usage by other functions. Hence, theNodevariable will be destroyed. This is because theNodevariable will be local and stored on the stack.If we were to declare a
Nodevariable, and then decide to delete it from the list, we will change the links in the linked list to remove it. However, theNodevariable will still be in memory.
The solution to these problems is to always declare a Node dynamically on the heap for linked lists.
13.2.3. Form a linked list dynamically#
To declare the nodes in a linked list dynamically, we need to follow some conventions. The first node should always be pointed by a pointer we will name head. The last node should always have NULL as its next value to identify it as the last node in the list.
We can change the code in the above figure as follows to dynamically allocate nodes.
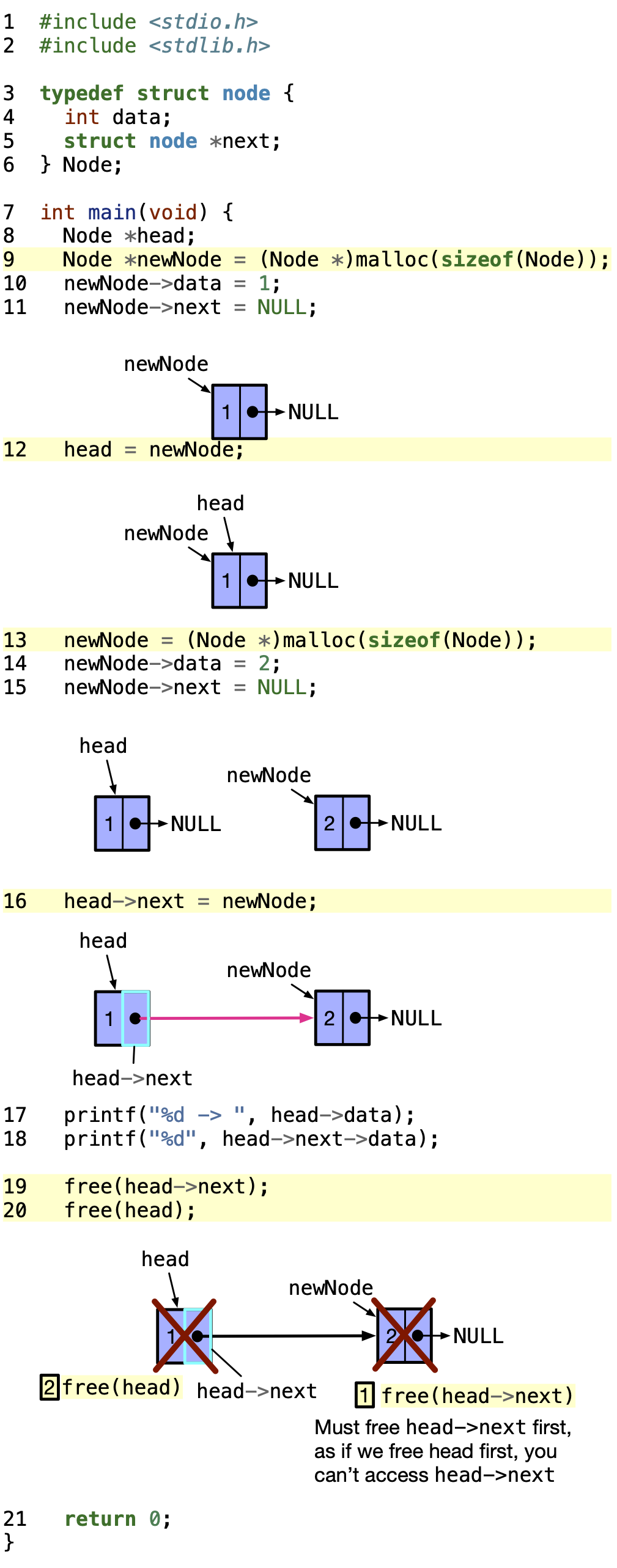
Output
1 -> 2
In line \(9\), we dynamically allocate a memory space on the heap of size sizeof(Node) bytes and assign the address of that space to newNode. We set the data and next of that Node to 1 and NULL respectively in lines \(10\) and \(11\).
In line \(12\), we make head point to what newNode points to. head is a pointer to a Node, and newNode is a pointer to a Node. Hence, we can assign newNode to head.
In line \(13\), we dynamically allocate a memory space on the heap of size sizeof(Node) bytes and assign the address of that space to newNode. We set the data and next of that Node to 2 and NULL respectively in lines \(14\) and \(15\).
In line \(16\), we make (*head).next point to what newNode points to. (*head).next is a pointer to a Node, and newNode is a pointer to a Node. This links the node with data 1 to the node with data 2.
In lines \(17\) and \(18\), we print the data of the node pointed to by head and the data of the node pointed to by (*head).next respectively.
To free the dynamic memory, we free all the space allocated on heap, which is pointed to by head and head->next. The order of free is critical. In case, newNode is not pointing to the second node, and we free(head) first, then head will be pointing to a freed memory space. Hence, we won’t be able to access the next in head and do free(head->next). Therefore, we should first free(head->next) then free(head).
It is silly to have to repeat code/statements to add or delete nodes to a linked list. We can write a set of functions that allow us to do operations on a linked list. In the next few sections, we will be developing functions to help us implement these operations.
Visualize Code
#include <stdio.h> #include <stdlib.h>
typedef struct node { int data; struct node *next; } Node;
int main(void) { Node *head; Node *newNode = (Node *)malloc(sizeof(Node)); newNode->data = 1; newNode->next = NULL;
head = newNode;
newNode = (Node *)malloc(sizeof(Node));
newNode->data = 2;
newNode->next = NULL;
head->next = newNode;
printf("%d -> ", head->data);
printf("%d", head->next->data);
free(head->next);
free(head);
return 0;
}
13.2.4. Checkpoint#
Quiz
0 Questions